
Summary - Learning to Align and Translate
Neural Machine Translation by Jointly Learning to Align and Translate (2014)
Authors: Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
Abstract
-
Task: Machine Translation (English - French).
-
Objective : argmaxy p ( y x ), maximize the conditional probability of target sentence y given source words x. -
Encoder - decoder architectures were introduced as an alternative to phrase-based models.
-
Encoder produces a fixed-length vector for an input sequence, and the decoder tries to generate an output sequence from that vector.
- Problem
- Difficult to capture all the information in a single vector, especially for longer sequence words.
- Solution
- Introducing “Attention mechanism” to the decoder.
Proposed Idea
-
Instead of generating fixed-length vectors, whenever a decoder generates an output, it searches (soft-search) among source words where the most relevant information is present.
-
We primarily use RNN as our fundamental component for encoder and decoders.
Implementation
- Encoder (BiLSTM) accepts previous hidden state (ht-1) and input word (xt)
- We are keeping only the hidden states, which we pass to next time step. equation, ht = f (xt , ht-1), where f is non-linear
- Decoder (BiLSTM) accepts context vector (ci), previous output (yi-1) and last hidden state (si-1).
- equation, yt = g (yt-1 , st , ct) , where g is non-linear
##
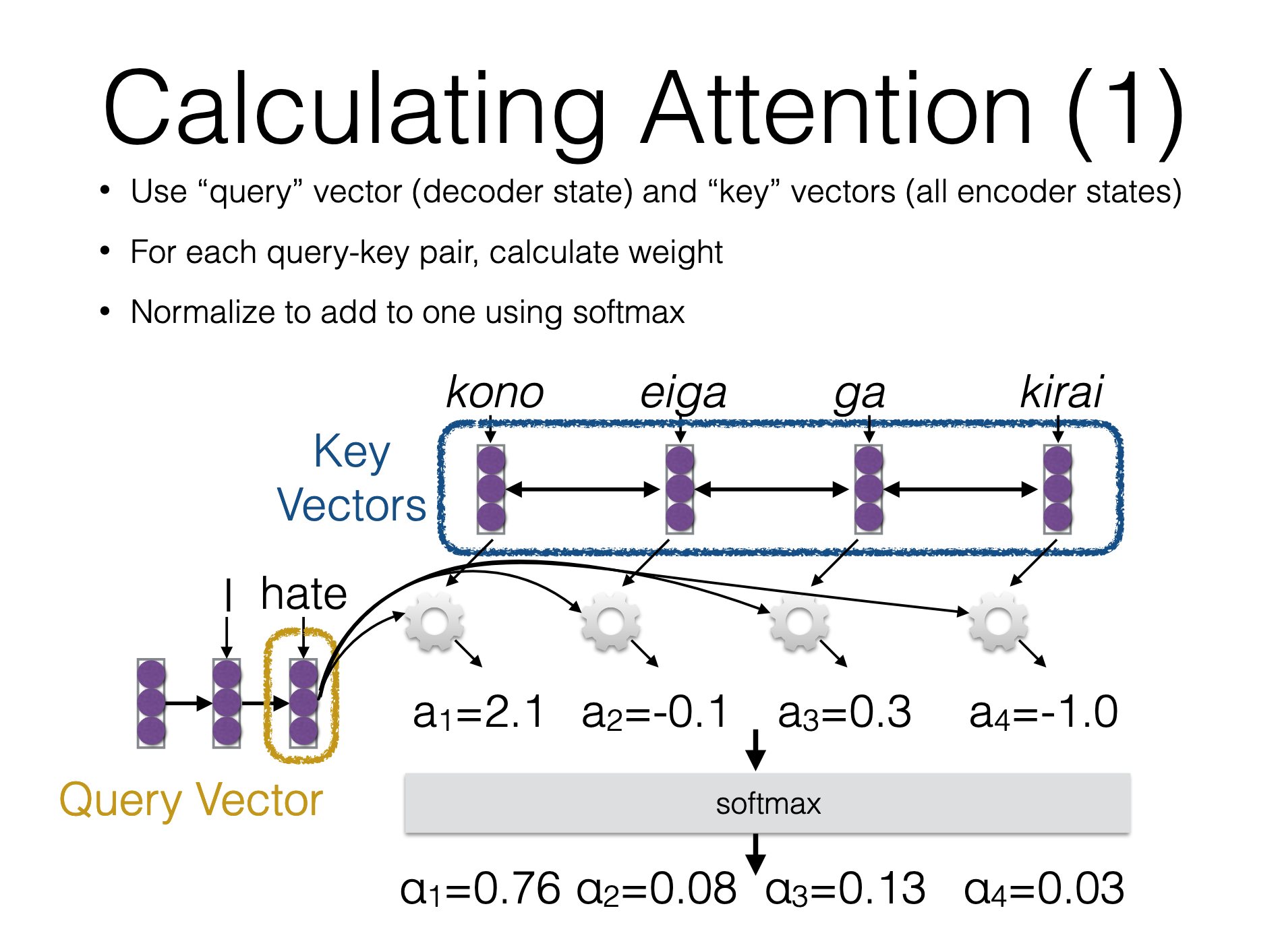 image source
##
image source
##
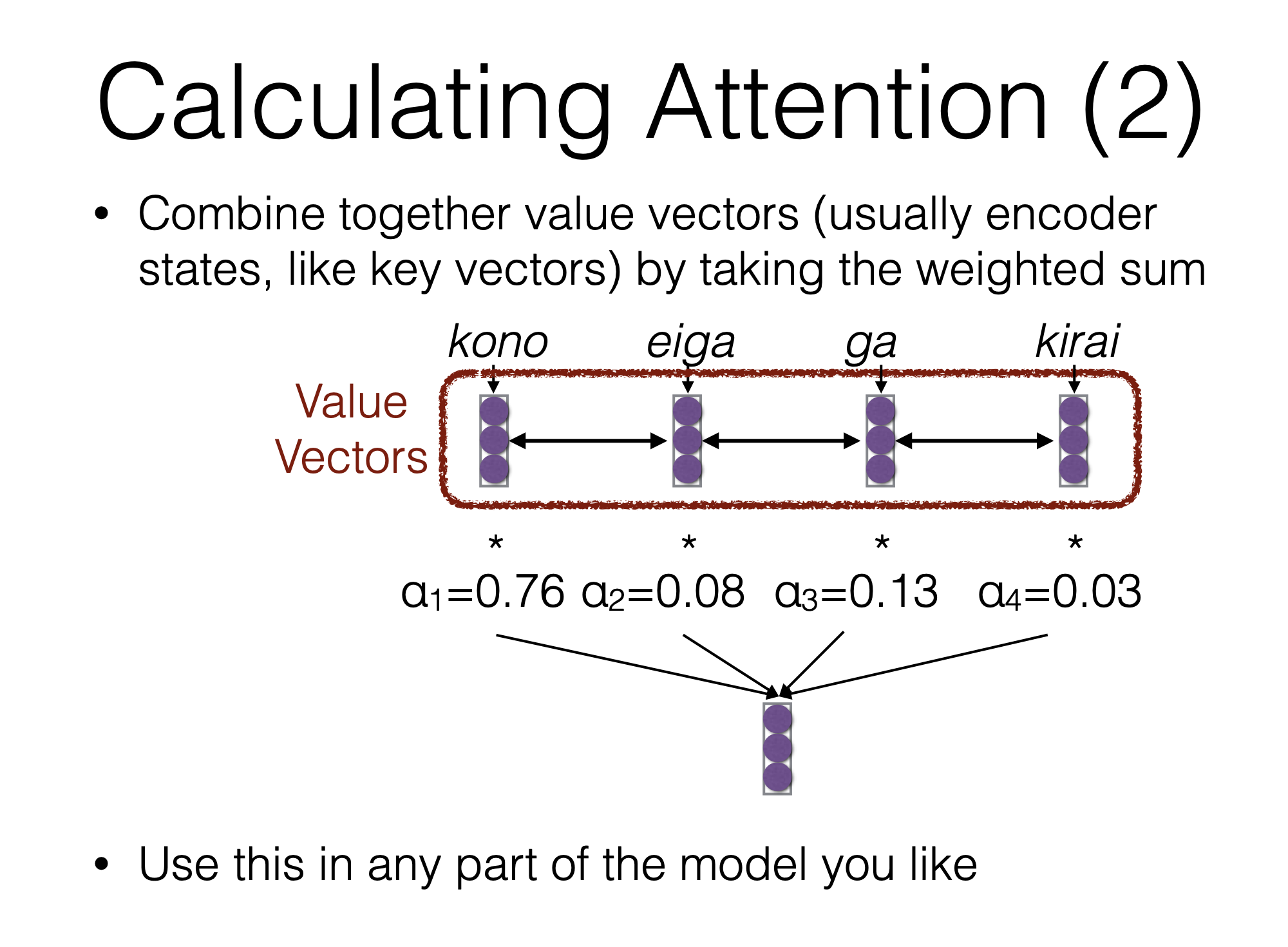 image source
image source
- STEPS
- Producing the Encoder Hidden States - Encoder produces hidden states of each element in the input sequence
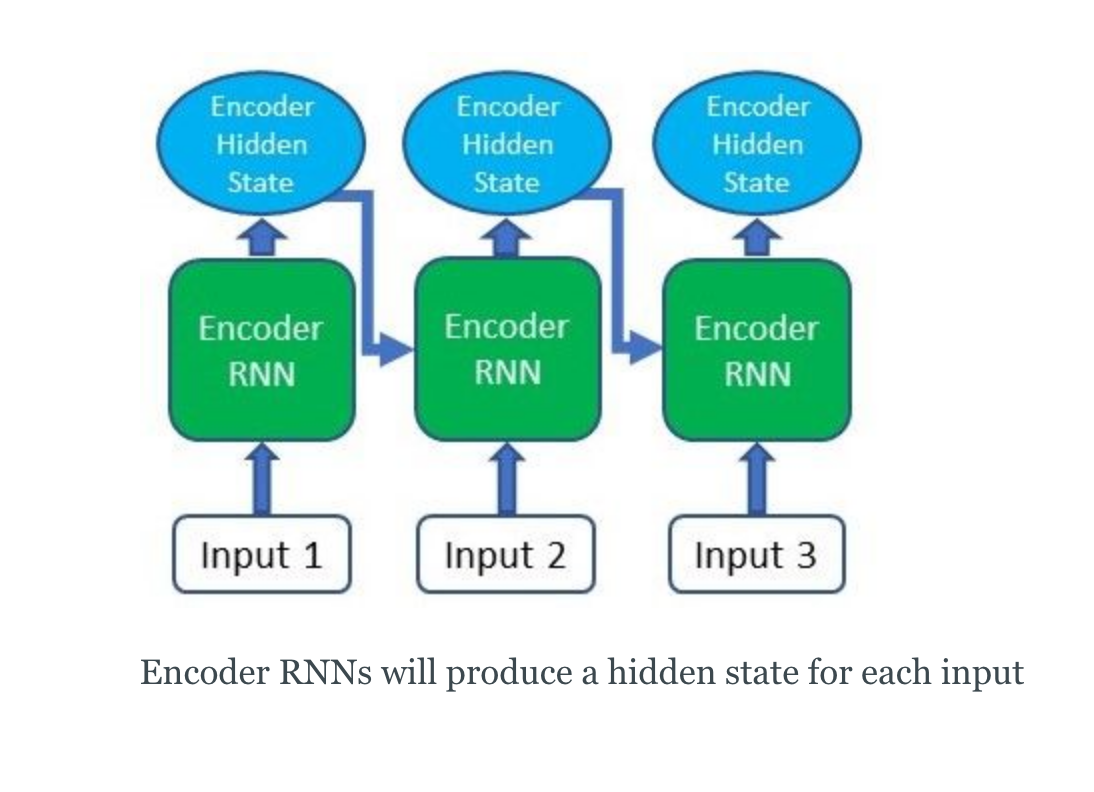 image source
image source - Calculating Alignment Scores between the previous decoder hidden state and each of the encoder’s hidden states are calculated (Note: The last encoder hidden state can be used as the first hidden state in the decoder)
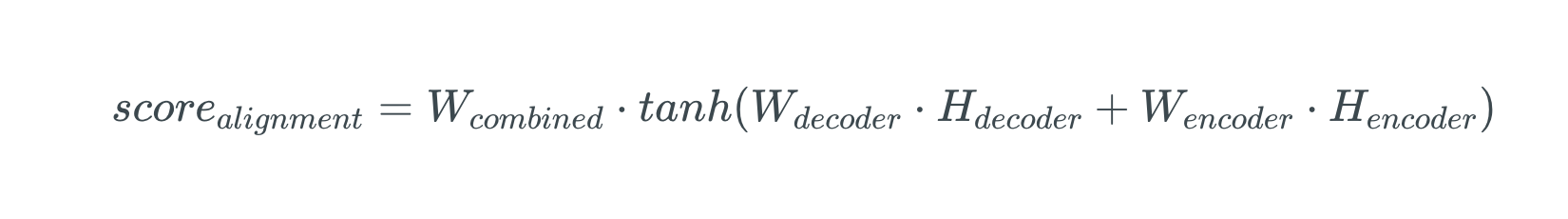 image source
image source - Softmaxing the Alignment Scores - the alignment scores for each encoder hidden state are combined and represented in a single vector and subsequently softmaxed
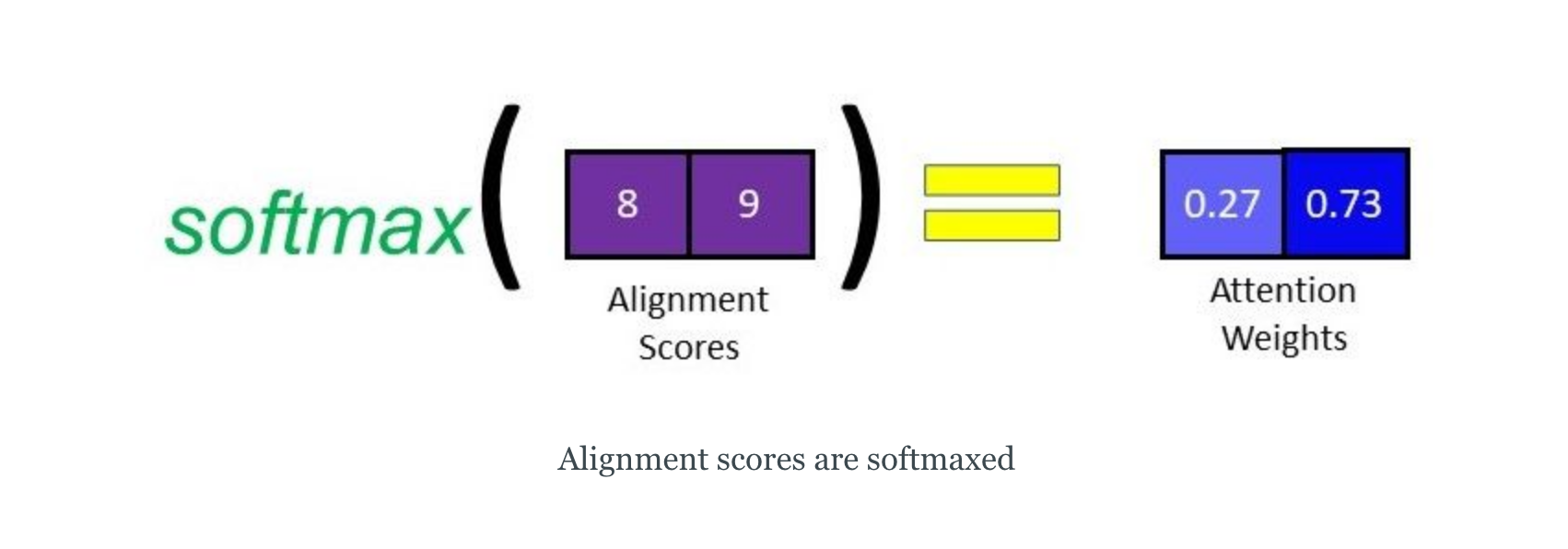 image source
image source - Calculating the Context Vector - the encoder hidden states and their respective alignment scores are multiplied to form the context vector
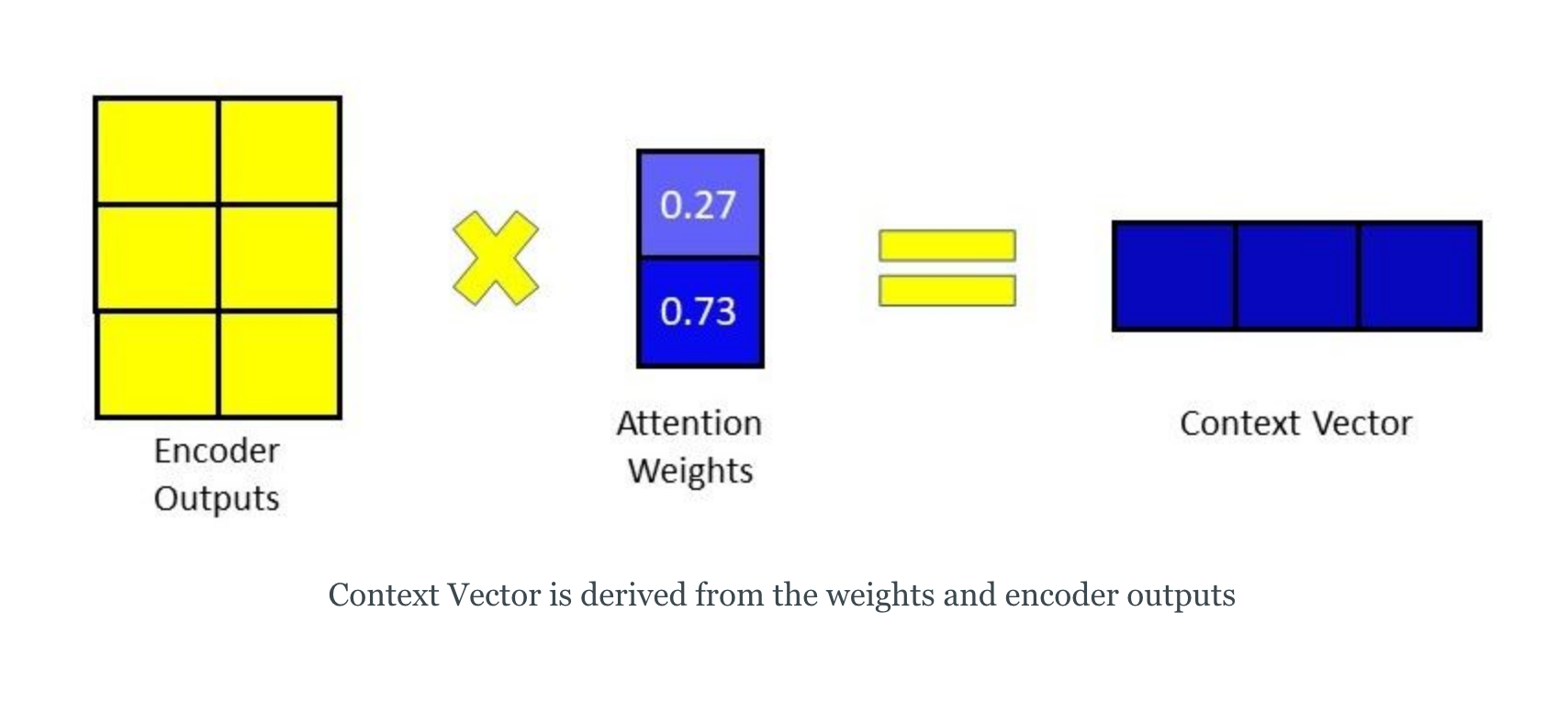 image source
image source - Decoding the Output - the context vector is concatenated with the previous decoder output and fed into the Decoder RNN for that time step along with the previous decoder hidden state to produce a new output
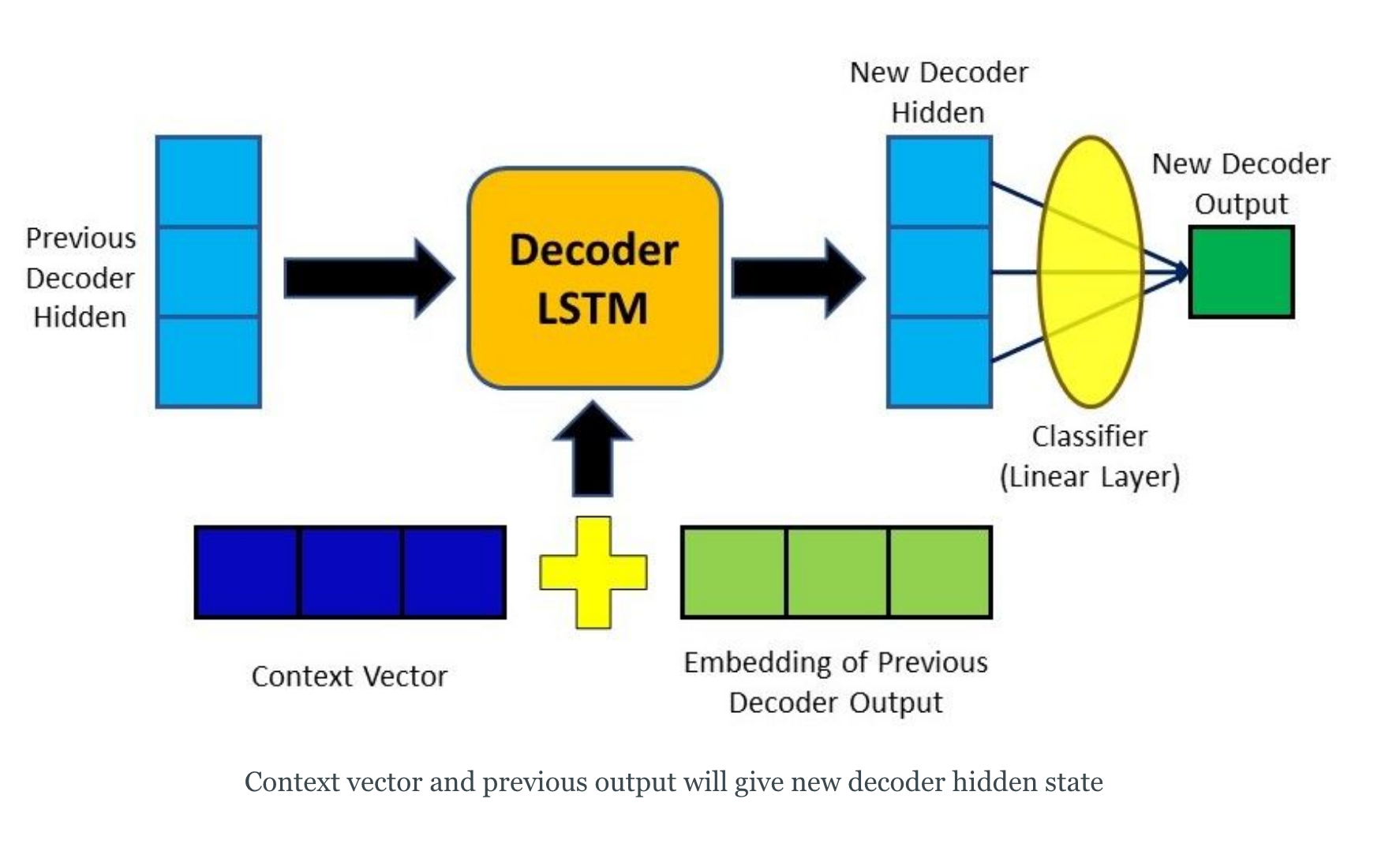 image source
image source - The process (steps 2-5) repeats itself for each time step of the decoder until an token is produced or output is past the specified maximum length
- Producing the Encoder Hidden States - Encoder produces hidden states of each element in the input sequence
- Overall Architecture
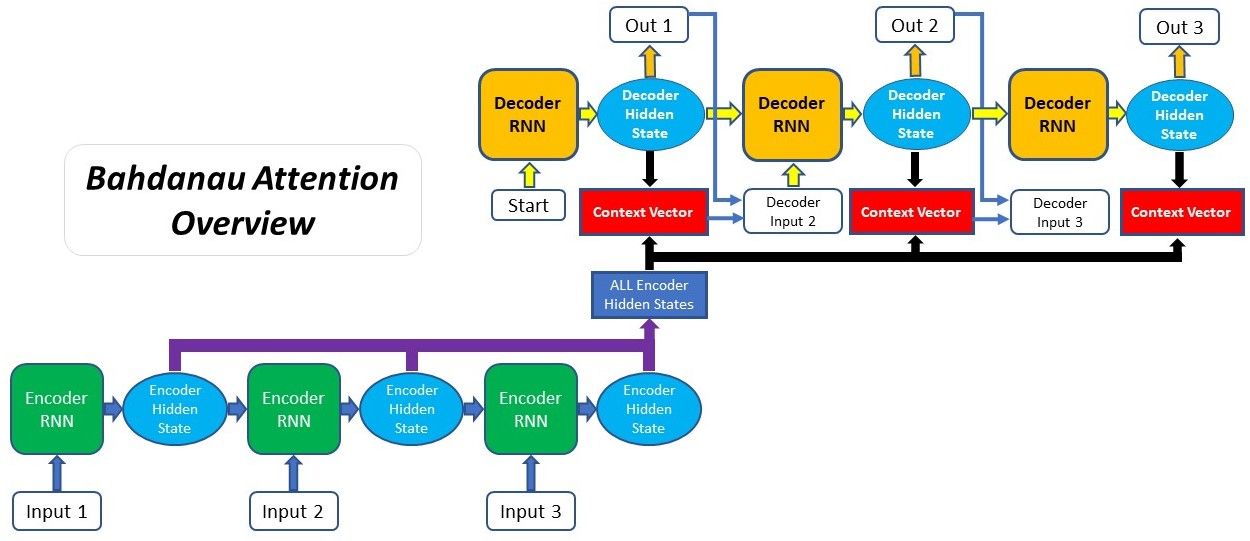 image source
image source
Training
- Corpus - 348M words
- Experimenting with 2 models
- RNNenc-dec (RNN encoder-decoder without attention)
- RNNsearch (RNN encoder-decoder with attention)
- On 2 data setting, sentences of
- Length up to 30 words -> RNNencdec-30, RNNsearch-30
- Length up to 50 words -> RNNencdec-50, RNNsearch-50
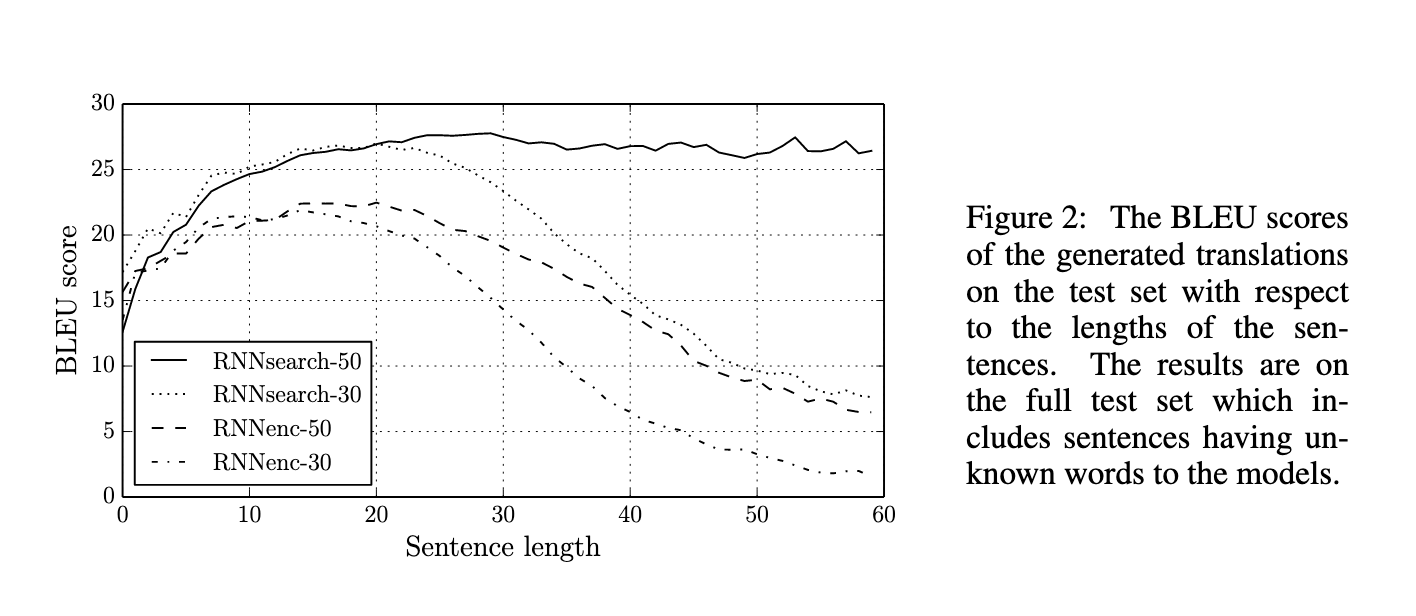
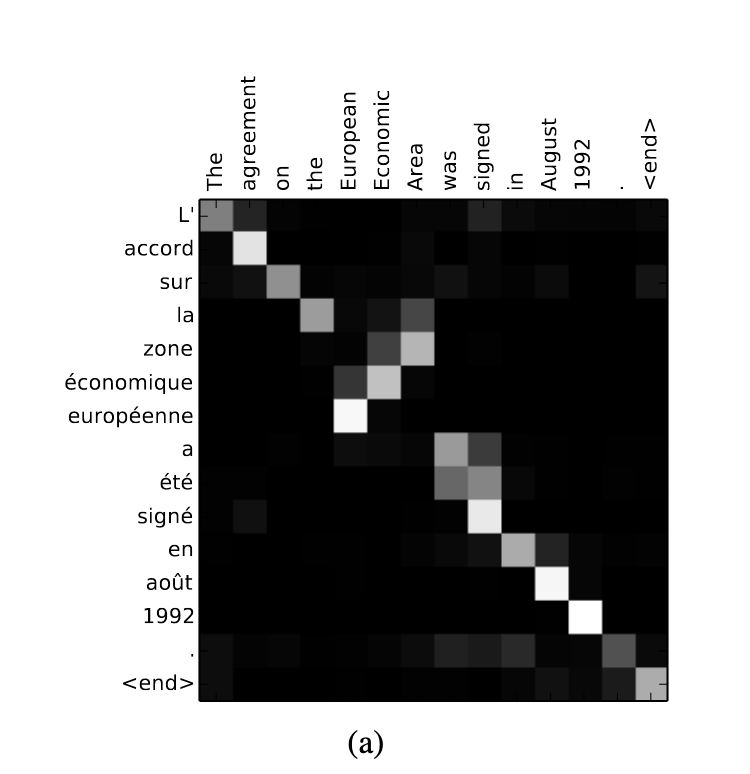
Output
Paper Link
Useful Links
References
These following papers inspire most of the paperwork.
- Kalchbrenner, N. and Blunsom, P. (2013). Recurrent continuous translation models. InProceedingsof the ACL Conference on Empirical Methods in Natural Language Processing (EMNLP), pages1700–1709. Association for Computational Linguistics.
- Sutskever, I., Vinyals, O., and Le, Q. (2014). Sequence to sequence learning with neural networks.InAdvances in Neural Information Processing Systems (NIPS 2014).
- Cho, K., van Merri ̈enboer, B., Bahdanau, D., and Bengio, Y. (2014b). On the properties of neuralmachine translation: Encoder–Decoder approaches. InEighth Workshop on Syntax, Semanticsand Structure in Statistical Translation. to appear.