Summary - Transformer
Research Paper - Attention Is All You Need
Authors - Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, LukaszKaiser, Illia Polosukhin.
Introduction
Earlier Sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder, encoder and decoder are connected through an attention mechanism.
Transformer - Overview
- Transformer, based solely on attention mechanisms draws global dependencies between input and output, dispensing with recurrence and convolutions.
- Superior in quality while being more parallelizable and requiring significantly less time to train.

Background
- ByteNet and ConvS2S, all of which use convolutional neural networks, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions.
- This makes it more difficult to learn dependencies between distant positions.
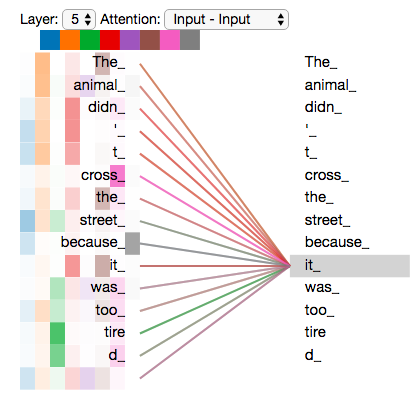
- Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.

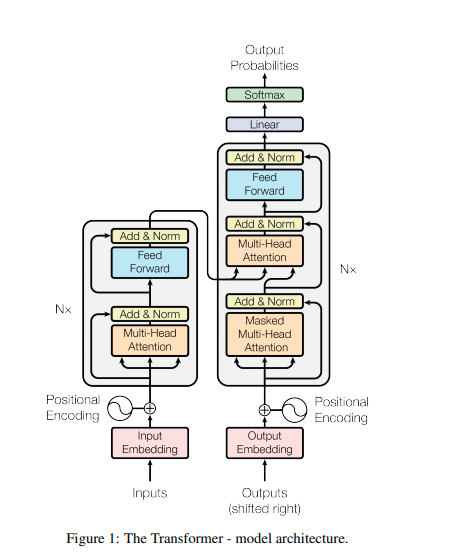
Architecture
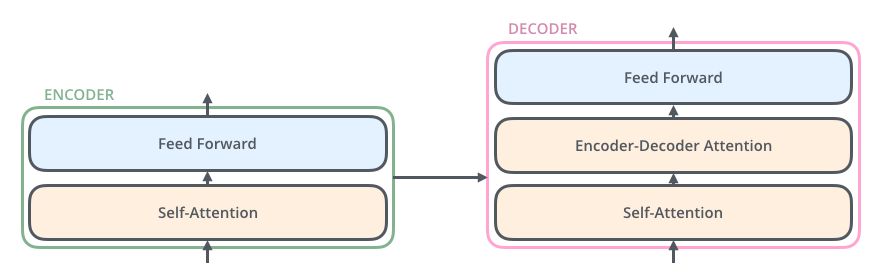
- Stacked self-attention and point-wise, fully connected layers for both the encoder and decoder.
Encoder
- The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers.
- The first is a multi-head self-attention mechanism and the second is a simple, positionwise fully connected feed-forward network. A residual connection is employed around each of the two sub-layers, followed by layer normalization.
- The output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself.
- To facilitate residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
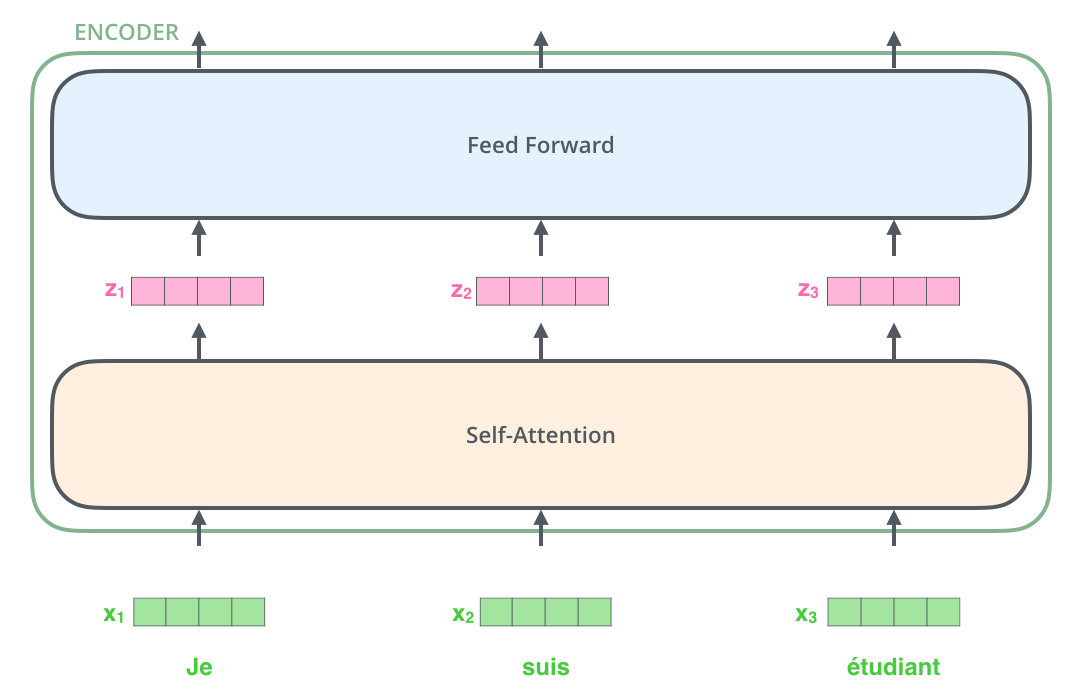
- The word in each position flows through its own path in the encoder. There are dependencies between these paths in the self-attention layer.
- The feed-forward layer does not have those dependencies and thus the various paths can be executed in parallel while flowing through the feed-forward layer.
Decoder
- The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
- The self-attention sub-layer in the decoder stack is modified to prevent positions from attending to subsequent positions.
- This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
Attention
- An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.
- They’re abstractions that are useful for calculating and thinking about attention.
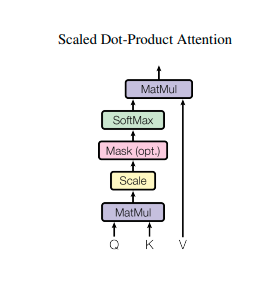
- The input consists of queries and keys of dimension dq,dk and values of dimension dv.
- The dot products of the query with all keys are computed, divided each by dk(1/2) and applied a softmax function to obtain the weights on the values. Attention(Q, K, V ) = softmax(QKT/ dk(1/2))V
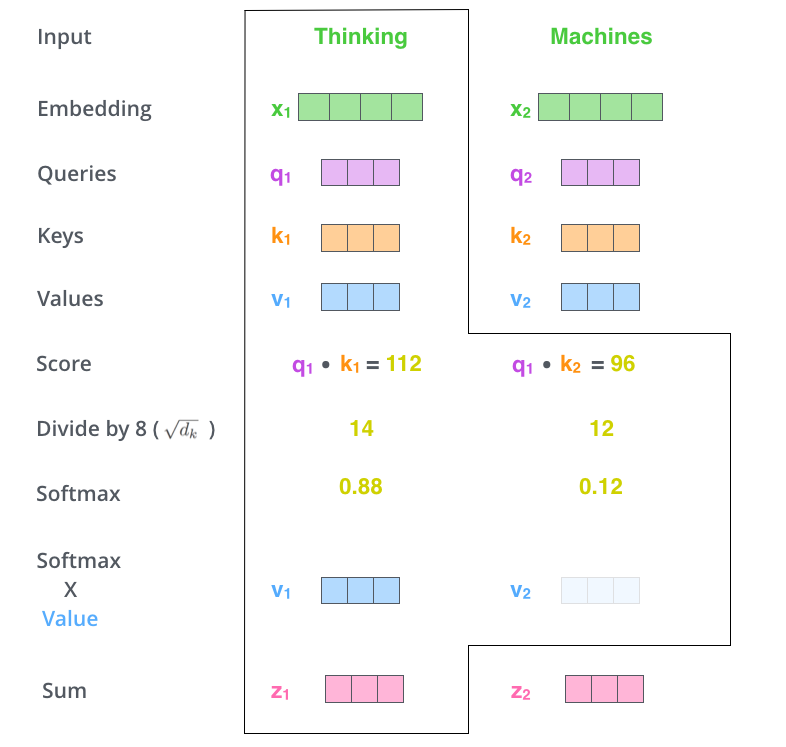
- The intuition behind value vectors is to keep intact the values of the word we want to focus on, and drown-out irrelevant words.(by multiplying them by tiny numbers like 0.001, for example)
- However, all these calculations are done in matrix form for faster processing.
Multi-Headed Self-Attention
- Instead of performing a single attention function with dmodel-dimensional keys, values and queries, it is beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dq, dk and dv dimensions, respectively.
- It gives the attention layer multiple “representation subspaces” i.e., multiple sets of Query/Key/Value weight matrices. (the Transformer uses eight attention heads, so we end up with eight sets for each encoder/decoder)

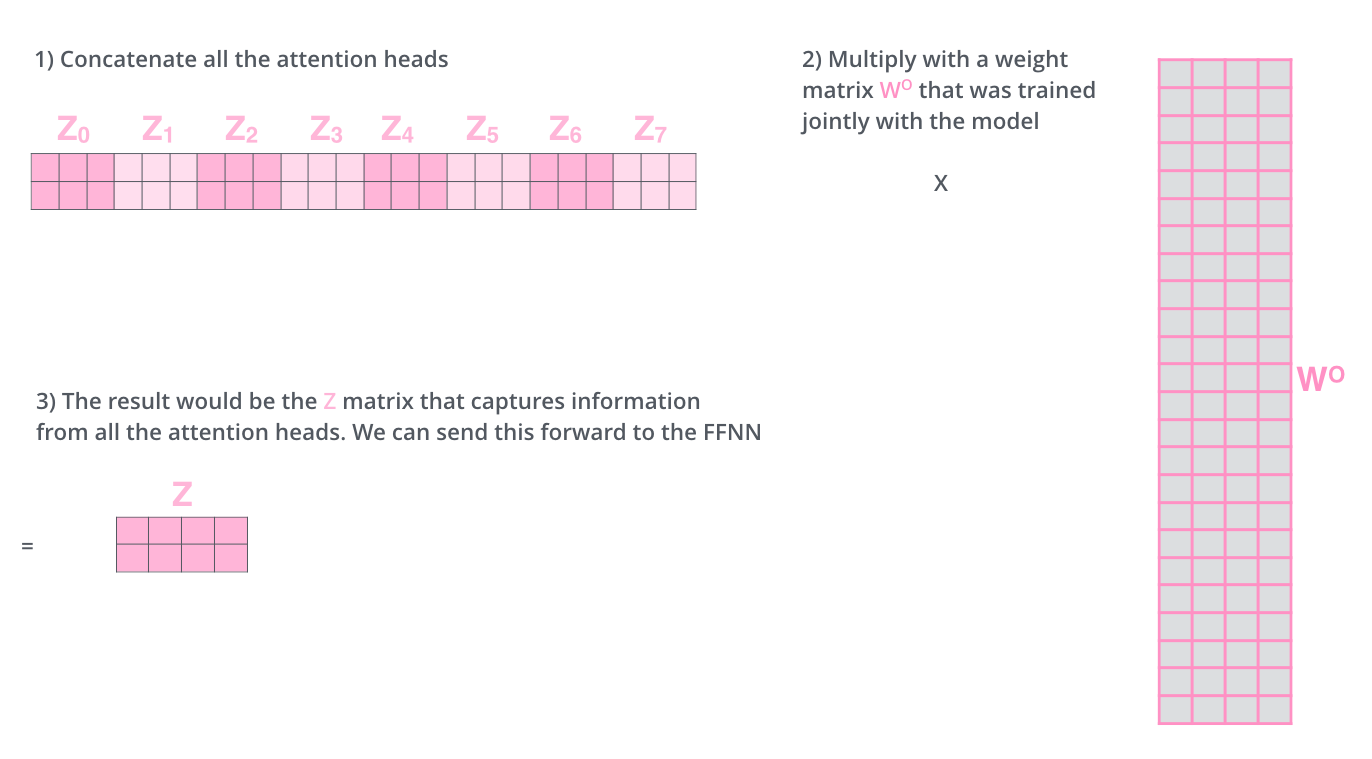
- On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected.
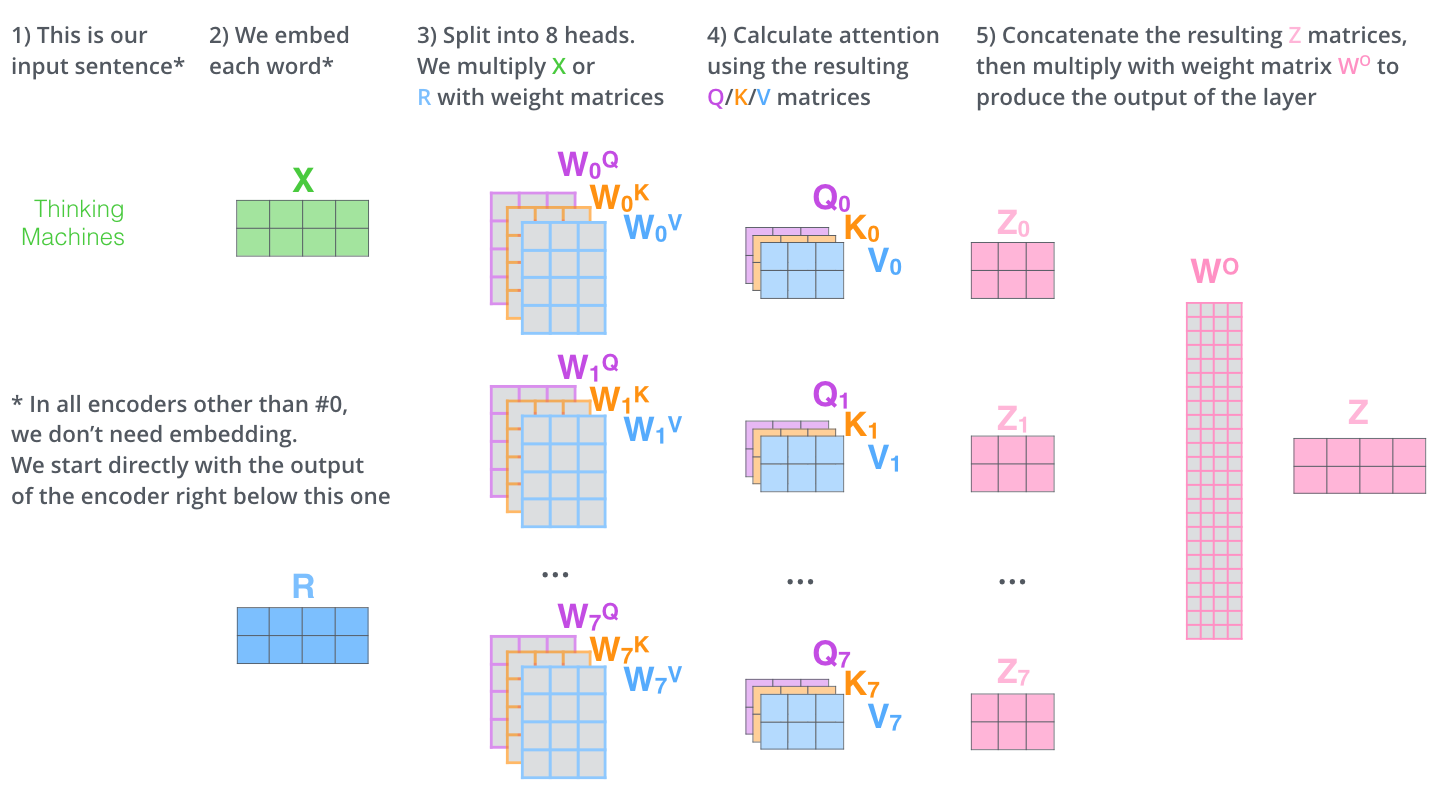
- If all the attention heads are added to the picture, it can be harder to interpret
Position-wise Feed-Forward Networks and Residual Network
- In addition to attention sub-layers, each of the layers in the encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically.
- This consists of two linear transformations with a ReLU activation in between i.e., FFN(x) = max(0, xW1 + b1)W2 + b2
Interpreting Decoder :
- The encoder start by processing the input sequence. The output of the top encoder is then transformed into a set of attention vectors K and V. These are to be used by each decoder in its “encoder-decoder attention” layer which helps the decoder focus on appropriate places in the input sequence.
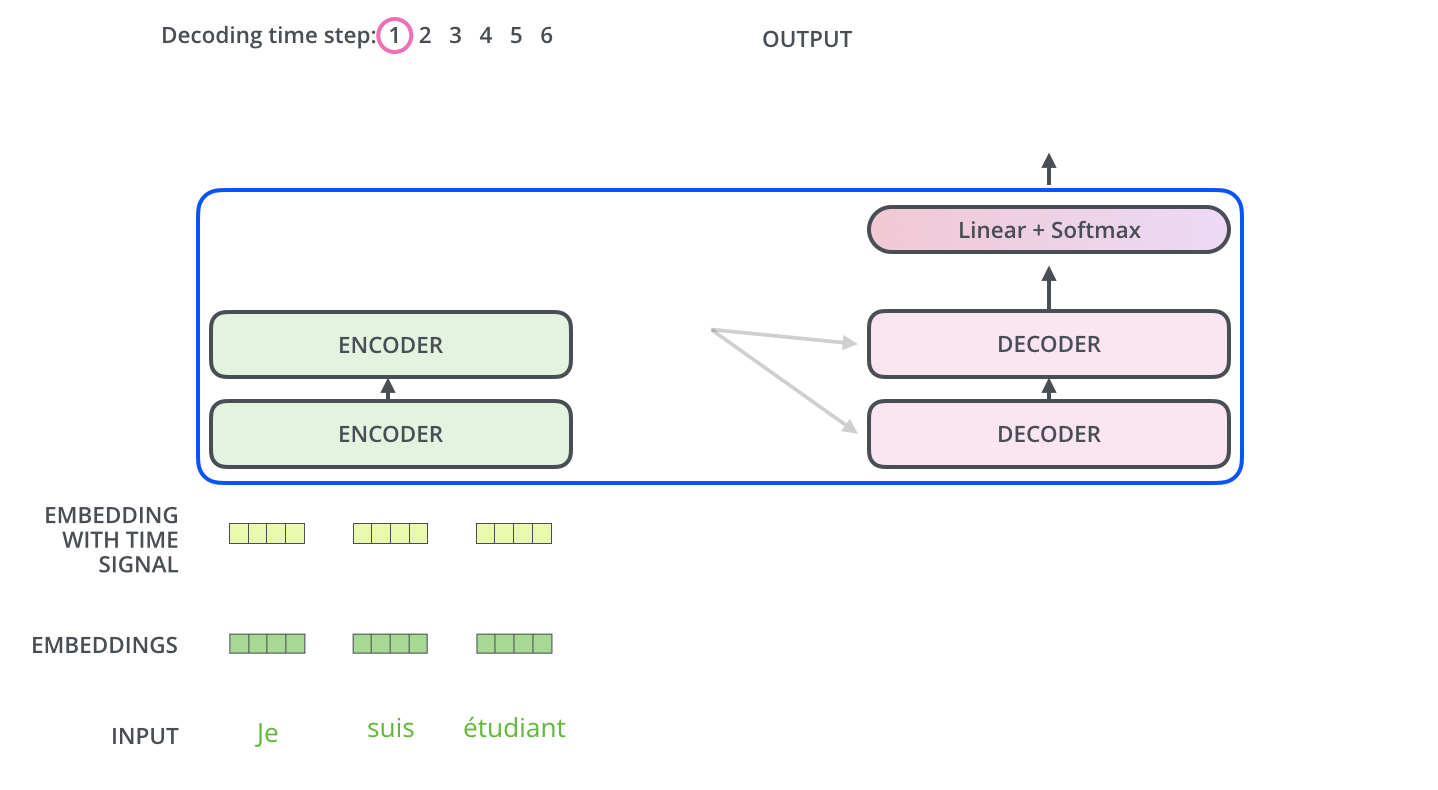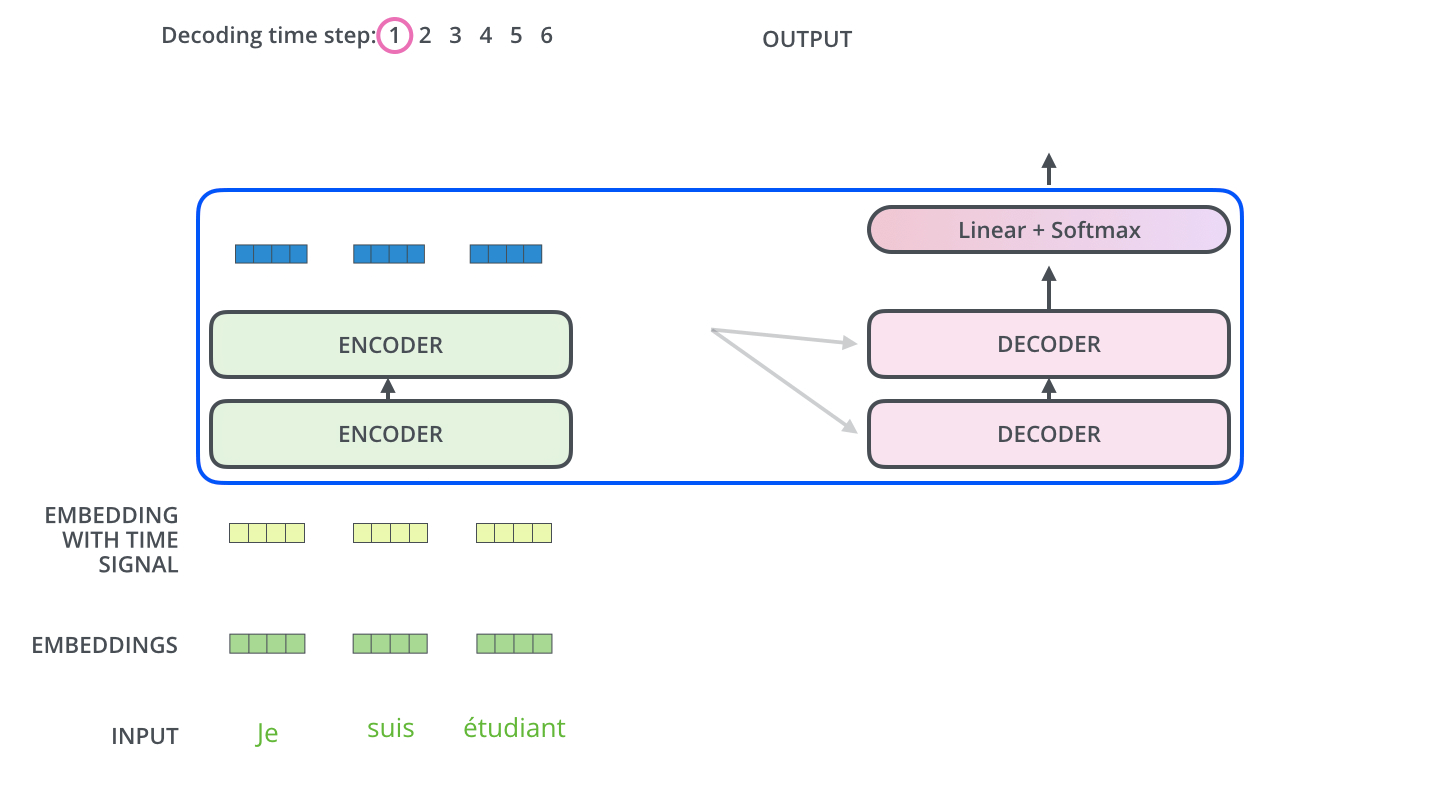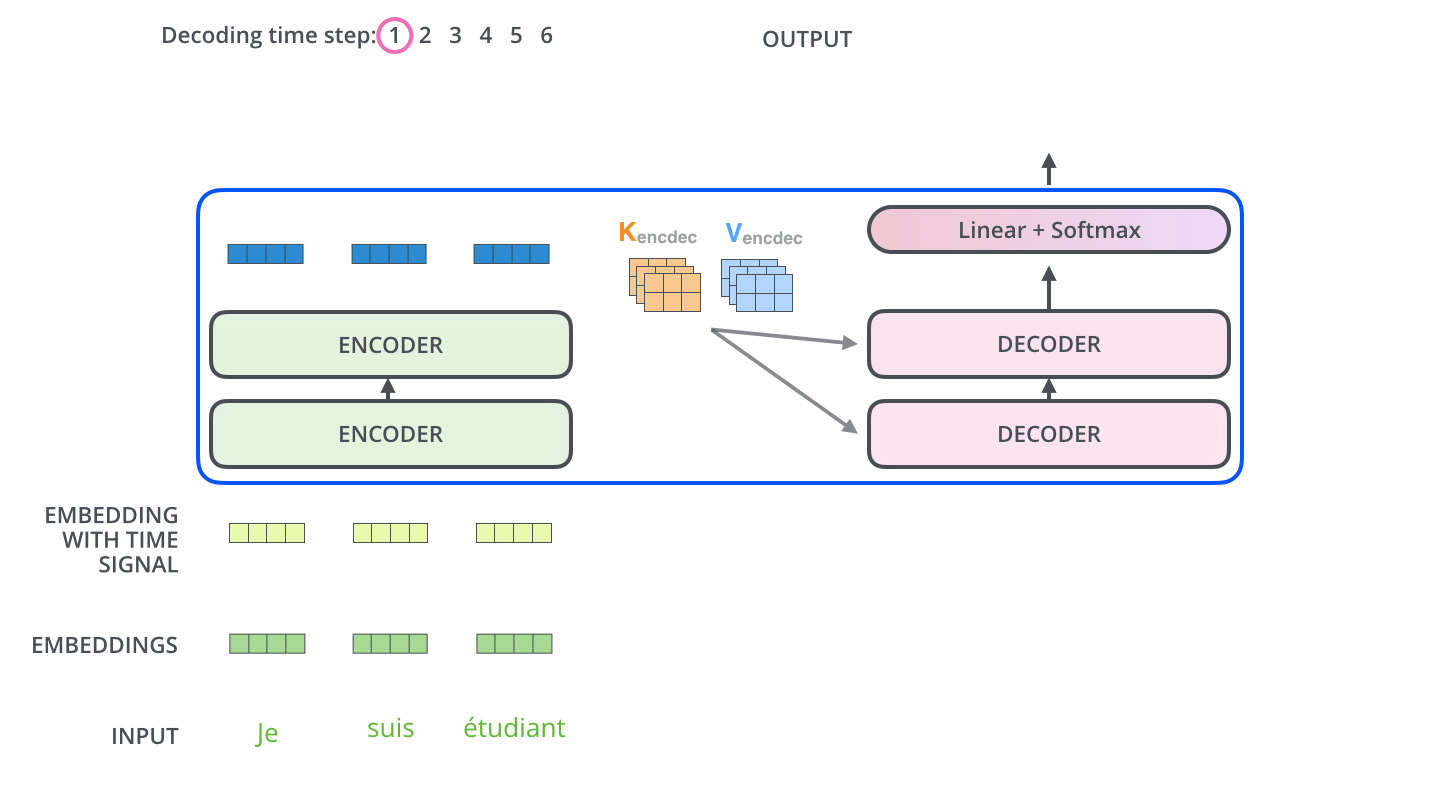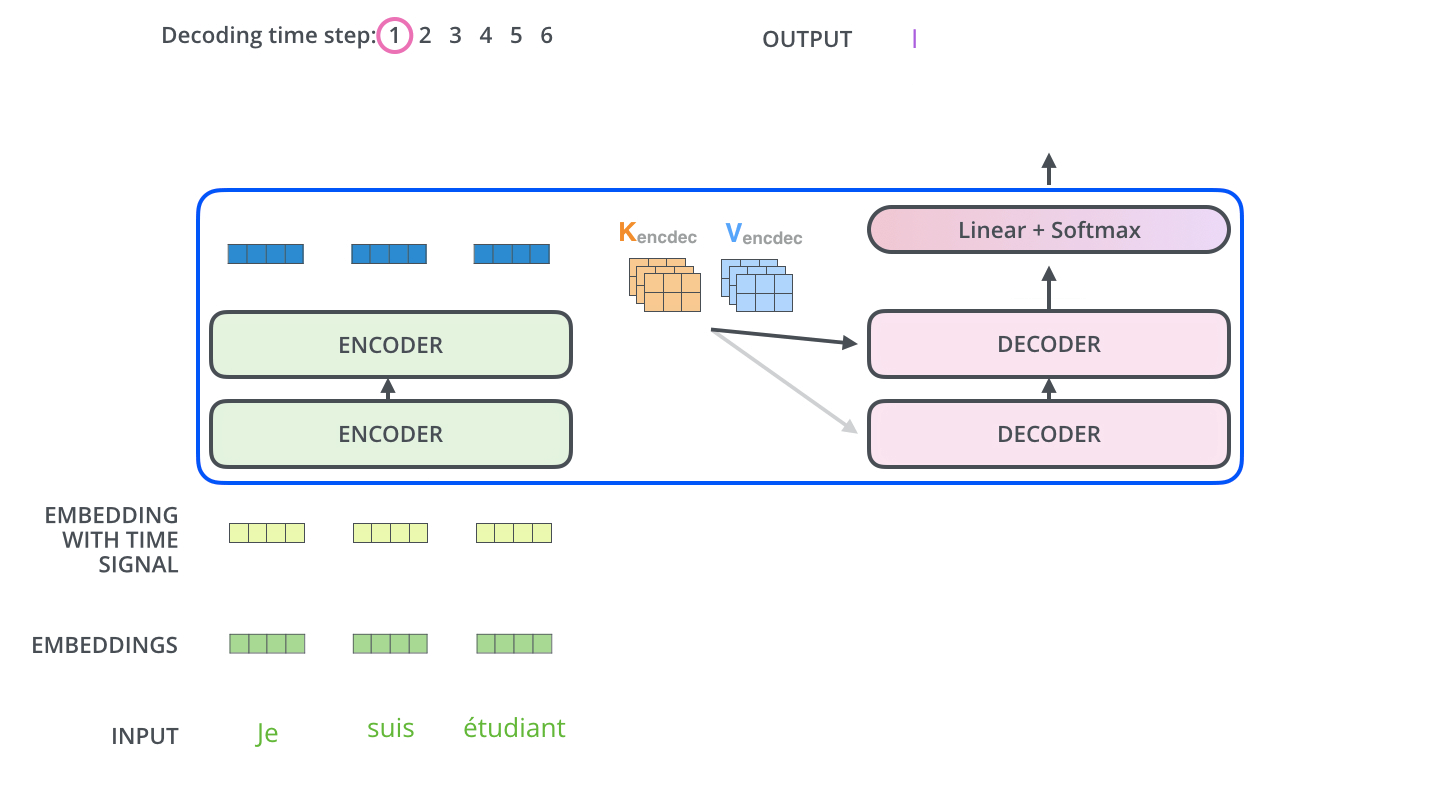
- The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack.
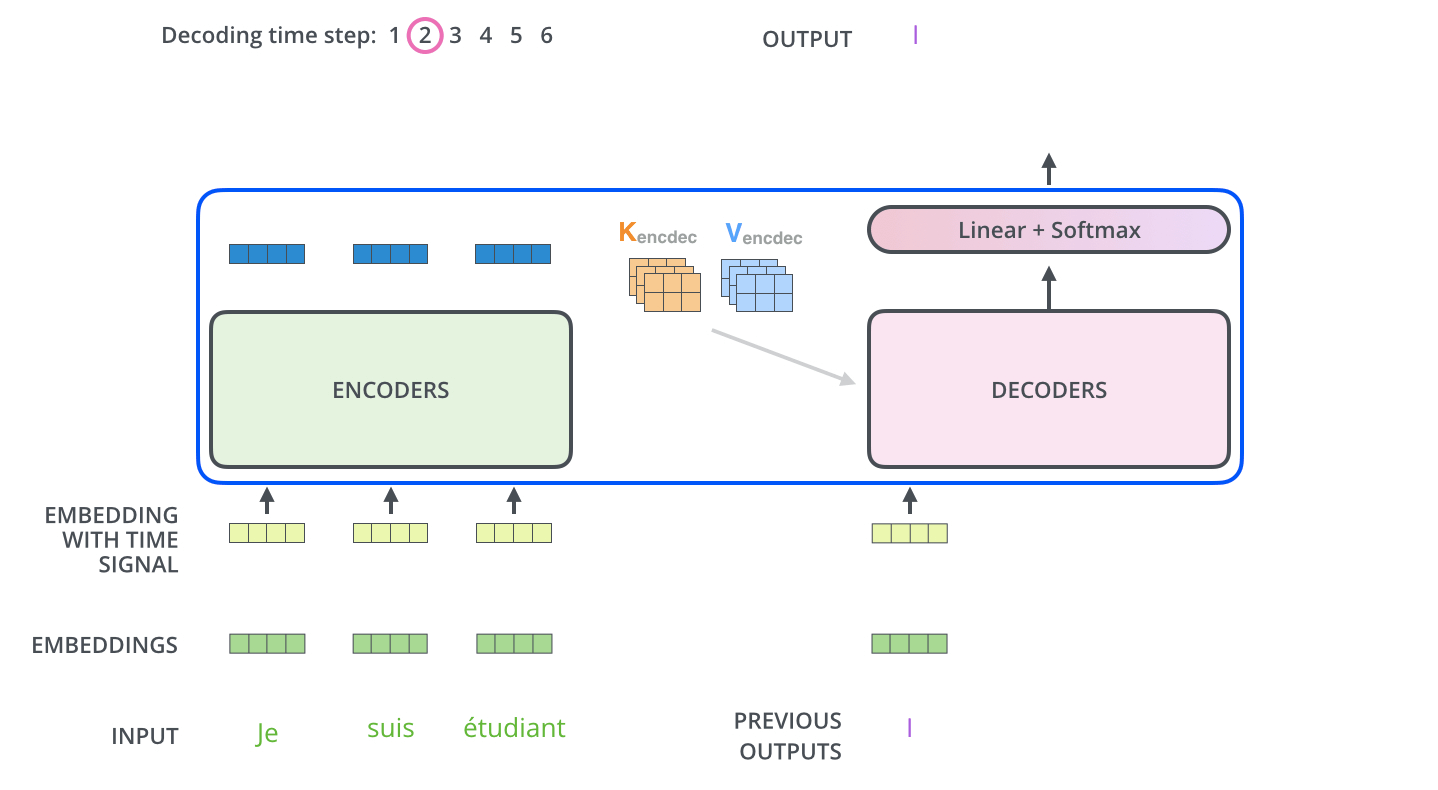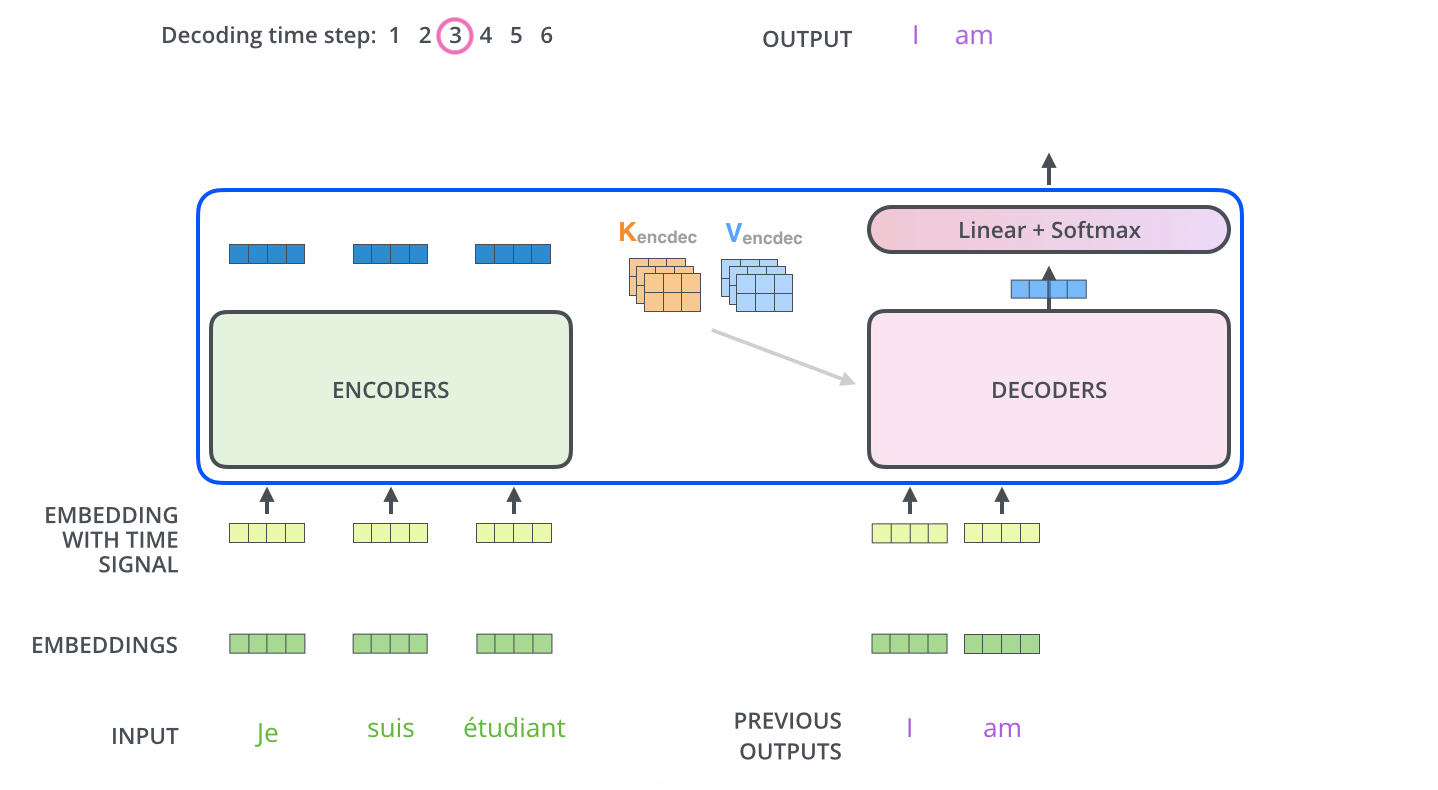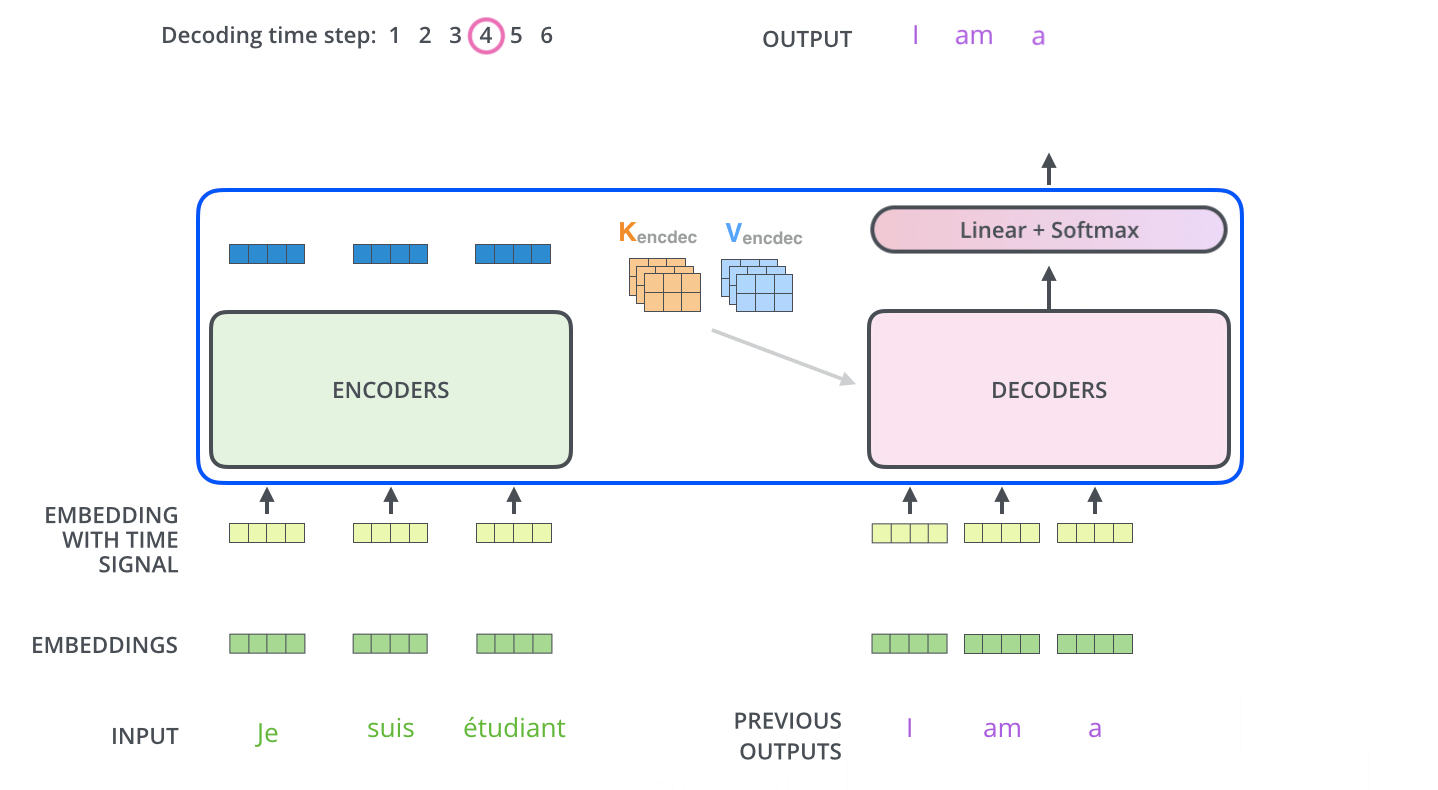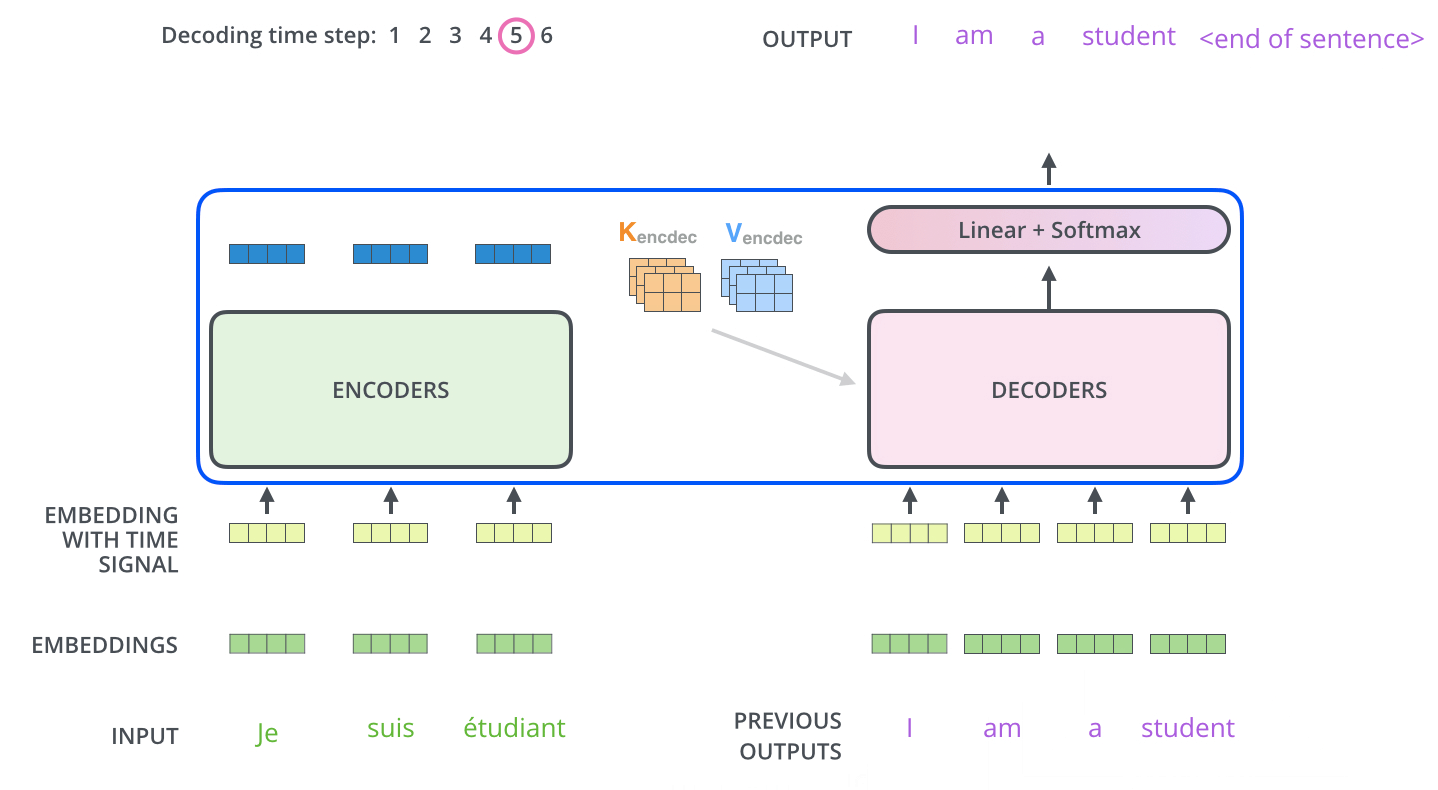
- The decoding steps repeat the process until a special symbol is reached indicating the transformer decoder has completed its output. The output of each step is fed to the bottom decoder in the next time step and the decoders bubble up their decoding results just like the encoders did.
- Just like the encoder inputs, decoder inputs are embedded and added positional encoding to indicate the position of each word.
- During training of NMT, generally teacher forcing technique is used.
Embeddings and Softmax
- Similarly to other sequence transduction models, learned embeddings are used to convert the input tokens and output tokens to vectors of dimension dmodel.
- Learned linear transformation and softmax function are used to convert the decoder output to predicted next-token probabilities.
Positional encoding
- Since Transformer contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, some information needs to be injected about the relative or absolute position of the tokens in the sequence.
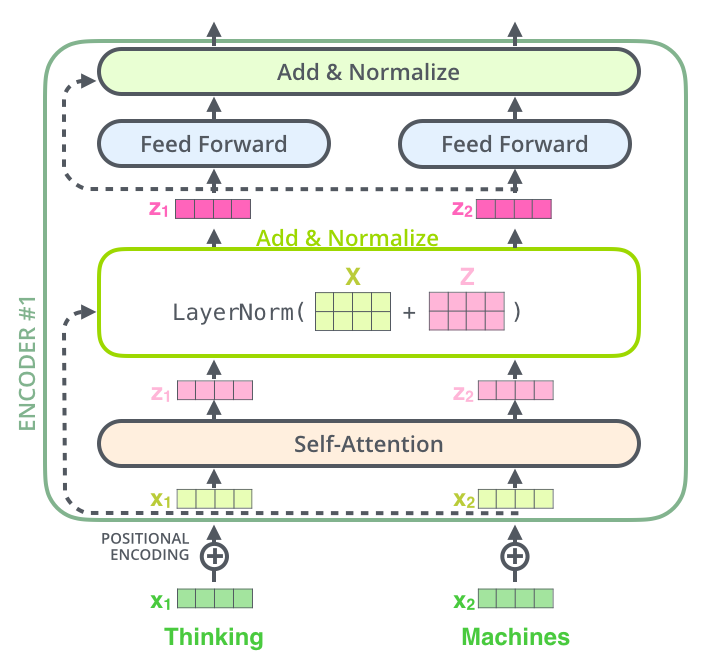
- To this end, “positional encodings” to the input embeddings are added at the bottoms of the encoder and decoder stacks. E(pos,2i) = sin(pos/10000^(2i/dmodel))
- The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention.
Legacy
- Many Language Models in NLP are based on Transformer and its Multi-headed attention. (as of 2019)
Images source
References
- The Illustrated Transformer
- Attention Is All You Need
- Hands-on and visualizing Attentions via Jupyter Notebook
- The Annotated Transformer from Harvard NLP